Let’s be honest. The cloud-native promise is intoxicating: infinite scale, rapid innovation, resilience. But that promise can come with a nasty side effect: sticker shock. And, increasingly, a nagging feeling about the environmental footprint of all those spinning containers and humming data centers.
Here’s the deal. Cost optimization and sustainability in cloud-native software aren’t separate battles. They’re two sides of the same coin. Wasting compute cycles burns cash and carbon. An efficient, lean application is inherently more sustainable. So, let’s dive into the strategies that tackle both, turning your architecture from a resource hog into a model of efficiency.
Right-Sizing: The Foundation of Everything
It sounds obvious, but it’s the most common misstep. You provision for peak load, just to be safe. But that’s like heating an entire stadium for a weekly book club meeting. The rest of the time, you’re paying for—and powering—empty space.
Right-sizing means continuously matching your resource allocations (CPU, memory) to your actual workload demands. Cloud-native tools are your best friend here.
Key Tactics for Effective Right-Sizing:
- Leverage Horizontal Pod Autoscaling (HPA): This Kubernetes native feature automatically adjusts the number of pod replicas based on CPU or custom metrics. It’s reactive, scaling out when demand spikes and, crucially, scaling in when it drops.
- Implement Vertical Pod Autoscaling (VPA): While HPA handles the pod count, VPA adjusts the CPU and memory requests and limits of the pods themselves. It learns from your application’s behavior and recommends—or automatically applies—optimal resource specs.
- Embrace Spot Instances and Preemptible VMs: For fault-tolerant, batch, or stateless workloads, these interruptible compute options can slash costs by 60-90%. The trade-off? They can be reclaimed by the cloud provider with short notice. It’s a perfect example of a cloud-native cost optimization strategy that also reduces demand on always-on infrastructure.
The Idle Resource Tax (And How to Avoid It)
Think of an idle container or an underutilized VM as a leaky faucet. Drip, drip, drip goes your budget—and energy is being consumed for no real work. In a dynamic environment, things get forgotten. Development namespaces left running over weekends. Staging environments replicating production scale 24/7.
You need automated cleanup crews.
- Schedule-Based Shutdowns: Use simple cron jobs or cloud scheduler tools to automatically power down non-production environments during off-hours. No one needs a full-scale staging cluster at 2 AM on a Sunday.
- Implement TTL (Time-To-Live) for Ephemeral Resources: For CI/CD pipelines, temporary test environments, or developer sandboxes, define a lifespan. Tools like Kubernetes Jobs or namespaces with TTL controllers ensure they self-destruct after use, preventing zombie resources.
Architecting for Efficiency from the Ground Up
Optimization isn’t just about managing what you have; it’s about building smarter from the start. This is where sustainable cloud-native development truly takes root.
Go Serverless (Where It Makes Sense)
Serverless functions (AWS Lambda, Azure Functions, Google Cloud Run for containers) abstract away the server entirely. You pay per execution, down to the millisecond. Zero idle cost. The cloud provider’s auto-scaling becomes hyper-efficient, typically leading to a lower aggregate carbon footprint per transaction. It’s not a silver bullet for every workload—cold starts can be a pain—but for event-driven, sporadic tasks, it’s a powerhouse for efficiency.
Choose Efficient Data Stores and Patterns
Data is heavy. Moving it, storing it, querying it—it all consumes energy. Ask yourself: Do you need a massive SQL database for simple session storage? Probably not.
- Use the right tool for the job: Leverage caching (Redis, Memcached) aggressively to reduce repeated database hits. Consider lighter-weight data stores for specific needs.
- Mind the data gravity: Keep data processing close to the data source. Processing data in the same region or availability zone avoids costly and energy-intensive cross-network transfers.
- Archive and tier: Automatically move cold data to cheaper, lower-power storage tiers. It’s digital housekeeping that saves money and reduces the energy of primary storage arrays.
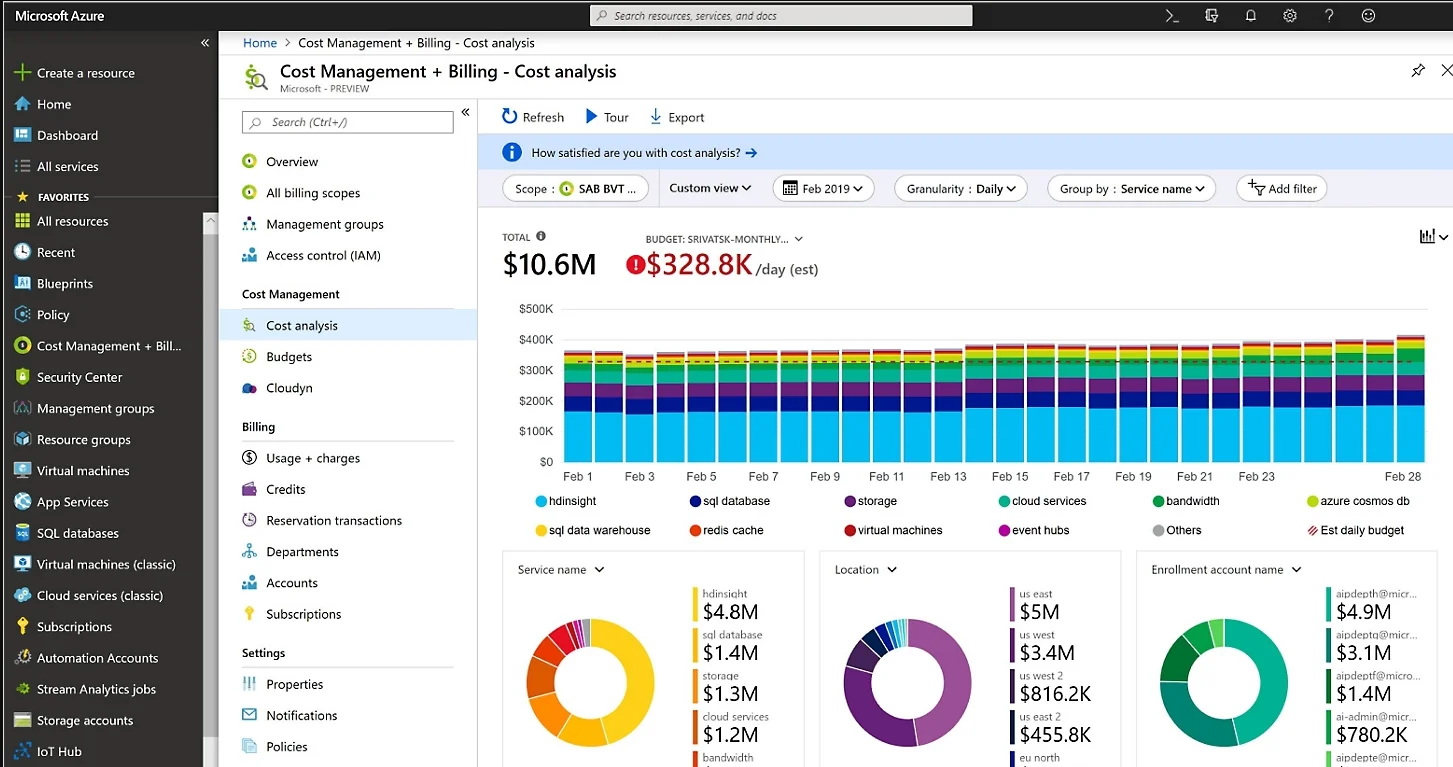
Visibility: You Can’t Optimize What You Can’t See
This is the linchpin. Without comprehensive observability, you’re flying blind. You need to move beyond basic cost dashboards to a unified view of cost, performance, and emissions.
| Tool Type | What It Does | Impact |
| FinOps Platforms (e.g., CloudHealth, Kubecost) | Allocates cloud spend to teams, projects, or even Kubernetes namespaces. Shows waste and provides optimization recommendations. | Creates accountability and pinpoints exact areas of overspend. |
| Observability Suites (e.g., Prometheus/Grafana, commercial APM) | Tracks application performance, resource utilization, and golden signals (latency, traffic, errors, saturation). | Identifies performance bottlenecks that cause resource bloat and inefficiency. |
| Carbon Tracking Tools (e.g., Cloud Carbon Footprint) | Translates cloud resource usage (compute, storage, networking) into estimated carbon emissions. | Makes the environmental impact tangible, linking engineering decisions to sustainability goals. |
When you can see that a particular microservice is using 70% CPU due to an inefficient loop, and you know it’s costing $2,300 a month, and you can see its carbon weight—well, fixing it becomes a multi-faceted priority.
Cultivating a FinOps & GreenOps Culture
All the tools in the world fail without the right culture. This isn’t just an ops problem. It’s a developer problem, a product problem, an architectural problem.
- Shift-Left on Cost and Carbon: Integrate cost and efficiency checks into the development lifecycle. Lint for infrastructure-as-code to flag over-provisioned resources. Include efficiency as a non-functional requirement in design reviews.
- Tag Everything Religiously: Resource tagging is the metadata that makes allocation and chargeback possible. It turns a nebulous cloud bill into an actionable report.
- Celebrate the Wins: When a team refactors a service, reducing its footprint and monthly cost by 40%, highlight it. Share the carbon savings. Make efficiency a core part of engineering excellence.
Honestly, it’s a mindset shift. From “just get it working in the cloud” to “get it working well in the cloud.”
The Bottom Line: A Virtuous Cycle
So, where does this leave us? The journey toward a cost-optimized and sustainable cloud-native estate isn’t a one-time project. It’s a continuous cycle of observe, optimize, and iterate.
You start by making things visible. You then rightsize, automate shutdowns, and choose efficient architectures. That frees up budget and reduces energy use. You reinvest those savings—maybe into carbon offset programs, or into further innovation. You measure again, and the cycle continues.
In the end, building for cost and building for sustainability aren’t constraints that limit innovation. They’re disciplines that fuel smarter, more resilient, and frankly, more responsible engineering. The cloud’s infinite canvas is still there—you’re just learning to paint on it with more precision, and with a lighter touch.